
NickTheGreek
-
Content Count
452 -
Joined
-
Last visited
-
Days Won
76 -
Feedback
N/A
Posts posted by NickTheGreek
-
-
The Awful Truth about sed
Sed is the ultimate stream editor. If that sounds strange, picture a stream flowing through a pipe. Okay, you can't see a stream if it's inside a pipe. That's what I get for attempting a flowing analogy. You want literature, read James Joyce.
Anyhow, sed is a marvelous utility. Unfortunately, most people never learn its real power. The language is very simple, but the documentation is terrible. The Solaris on-line manual pages for sed are five pages long, and two of those pages describe the 34 different errors you can get. A program that spends as much space documenting the errors as it does documenting the language has a serious learning curve.
Do not fret! It is not your fault you don't understand sed. I will cover sedcompletely. But I will describe the features in the order that I learned them. I didn't learn everything at once. You don't need to either.
-
Knowledge Base
What is grep, and how do I use it?
The
greputilities are a family of Unix tools, includinggrep,egrep, andfgrep, that perform repetitive searching tasks. The tools in thegrepfamily are very similar, and all are used for searching the contents of files for information that matches particular criteria. For most purposes, you'll want to usefgrep, since it's generally the fastest.The general syntax of the
grepcommands is:grep [-options] pattern [filename]
You can use
fgrepto find all the lines of a file that contain a particular word. For example, to list all the lines of a file namedmyfilein the current directory that contain the word "dog", enter at the Unix prompt:fgrep dog myfile
This will also return lines where "dog" is embedded in larger words, such as "dogma" or "dogged". You can use the
-woption with thegrepcommand to return only lines where "dog" is included as a separate word:grep -w dog myfile
To search for several words separated by spaces, enclose the whole search string in quotes, for example:
fgrep "dog named Checkers" myfile
The
fgrepcommand is case sensitive; specifying "dog" will not match "Dog" or "DOG". You can use the-ioption with thegrepcommand to match both upper- and lowercase letters:grep -i dog myfile
To list the lines of
myfilethat do not contain "dog", use the-voption:fgrep -v dog myfile
If you want to search for lines that contain any of several different words, you can create a second file (named
secondfilein the following example) that contains those words, and then use the-foption:fgrep -f secondfile myfile
You can also use wildcards to instruct
fgrepto search any files that match a particular pattern. For example, if you wanted to find lines containing "dog" in any of the files in your directory with names beginning with "my", you could enter:fgrep dog my*
This command would search files with names such as
myfile,my.hw1, andmystuffin the current directory. Each line returned will be prefaced with the name of the file where the match was found.By using pipes and/or redirection, you can use the output from any of these commands with other Unix tools, such as
more,sort, andcut. For example, to print the fifth word of every line ofmyfilecontaining "dog", sort the words alphabetically, and then filter the output through themorecommand for easy reading, you would enter at the Unix prompt:fgrep dog myfile | cut -f5 -d" " | sort | more
If you want to save the output in a file in the current directory named
newfile, enter:fgrep dog myfile | cut -f5 -d" " | sort > newfile
For more information about
grep,egrep, andfgrep, enter:man grep
At Indiana University, for personal or departmental Linux or Unix systems support, see At IU, how do I get support for Linux or Unix?
This is document afiy in the Knowledge Base.
Last modified on 2017-05-16 11:52:15.Contact us
For help or to comment, email the UITS Support Center. -
Exim Cheatsheet
Home Pics Personal Guitar Technical Contact
Here are some useful things to know for managing an Exim 4 server. This assumes a prior working knowledge of SMTP, MTAs, and a UNIX shell prompt.Message-IDs and spool files
The message-IDs that Exim uses to refer to messages in its queue are mixed-case alpha-numeric, and take the form of: XXXXXX-YYYYYY-ZZ. Most commands related to managing the queue and logging use these message-ids.There are three -- count 'em, THREE -- files for each message in the spool directory. If you're dealing with these files by hand, instead of using the appropriate exim commands as detailed below, make sure you get them all, and don't leave Exim with remnants of messages in the queue. I used to mess directly with these files when I first started running Exim machines, but thanks to the utilities described below, I haven't needed to do that in many months.
Files in /var/spool/exim/msglog contain logging information for each message and are named the same as the message-id.
Files in /var/spool/exim/input are named after the message-id, plus a suffix denoting whether it is the envelope header (-H) or message data (-D).
These directories may contain further hashed subdirectories to deal with larger mail queues, so don't expect everything to always appear directly in the top /var/spool/exim/input or /var/spool/exim/msglog directories; any searches or greps will need to be recursive. See if there is a proper way to do what you're doing before working directly on the spool files.
Basic information
Print a count of the messages in the queue:root@localhost# exim -bpc
Print a listing of the messages in the queue (time queued, size, message-id, sender, recipient):root@localhost# exim -bp
Print a summary of messages in the queue (count, volume, oldest, newest, domain, and totals):root@localhost# exim -bp | exiqsumm
Print what Exim is doing right now:root@localhost# exiwhat
Test how exim will route a given address:root@localhost# exim -bt alias@localdomain.com
user@thishost.com
<-- alias@localdomain.com
router = localuser, transport = local_delivery
root@localhost# exim -bt user@thishost.com
user@thishost.com
router = localuser, transport = local_delivery
root@localhost# exim -bt user@remotehost.com
router = lookuphost, transport = remote_smtp
host mail.remotehost.com [1.2.3.4] MX=0
Run a pretend SMTP transaction from the command line, as if it were coming from the given IP address. This will display Exim's checks, ACLs, and filters as they are applied. The message will NOT actually be delivered.root@localhost# exim -bh 192.168.11.22
Display all of Exim's configuration settings:root@localhost# exim -bP
Searching the queue with exiqgrep
Exim includes a utility that is quite nice for grepping through the queue, called exiqgrep. Learn it. Know it. Live it. If you're not using this, and if you're not familiar with the various flags it uses, you're probably doing things the hard way, like piping `exim -bp` into awk, grep, cut, or `wc -l`. Don't make life harder than it already is.First, various flags that control what messages are matched. These can be combined to come up with a very particular search.
Use -f to search the queue for messages from a specific sender:
root@localhost# exiqgrep -f [luser]@domain
Use -r to search the queue for messages for a specific recipient/domain:root@localhost# exiqgrep -r [luser]@domain
Use -o to print messages older than the specified number of seconds. For example, messages older than 1 day:root@localhost# exiqgrep -o 86400 [...]
Use -y to print messages that are younger than the specified number of seconds. For example, messages less than an hour old:root@localhost# exiqgrep -y 3600 [...]
Use -s to match the size of a message with a regex. For example, 700-799 bytes:root@localhost# exiqgrep -s '^7..$' [...]
Use -z to match only frozen messages, or -x to match only unfrozen messages.There are also a few flags that control the display of the output.
Use -i to print just the message-id as a result of one of the above two searches:
root@localhost# exiqgrep -i [ -r | -f ] ...
Use -c to print a count of messages matching one of the above searches:root@localhost# exiqgrep -c ...
Print just the message-id of the entire queue:root@localhost# exiqgrep -i
Managing the queue
The main exim binary (/usr/sbin/exim) is used with various flags to make things happen to messages in the queue. Most of these require one or more message-IDs to be specified in the command line, which is where `exiqgrep -i` as described above really comes in handy.Start a queue run:
root@localhost# exim -q -v
Start a queue run for just local deliveries:root@localhost# exim -ql -v
Remove a message from the queue:root@localhost# exim -Mrm <message-id> [ <message-id> ... ]
Freeze a message:root@localhost# exim -Mf <message-id> [ <message-id> ... ]
Thaw a message:root@localhost# exim -Mt <message-id> [ <message-id> ... ]
Deliver a message, whether it's frozen or not, whether the retry time has been reached or not:root@localhost# exim -M <message-id> [ <message-id> ... ]
Deliver a message, but only if the retry time has been reached:root@localhost# exim -Mc <message-id> [ <message-id> ... ]
Force a message to fail and bounce as "cancelled by administrator":root@localhost# exim -Mg <message-id> [ <message-id> ... ]
Remove all frozen messages:root@localhost# exiqgrep -z -i | xargs exim -Mrm
Remove all messages older than five days (86400 * 5 = 432000 seconds):root@localhost# exiqgrep -o 432000 -i | xargs exim -Mrm
Freeze all queued mail from a given sender:root@localhost# exiqgrep -i -f luser@example.tld | xargs exim -Mf
View a message's headers:root@localhost# exim -Mvh <message-id>
View a message's body:root@localhost# exim -Mvb <message-id>
View a message's logs:root@localhost# exim -Mvl <message-id>
Add a recipient to a message:root@localhost# exim -Mar <message-id> <address> [ <address> ... ]
Edit the sender of a message:root@localhost# exim -Mes <message-id> <address>
Access control
Exim allows you to apply access control lists at various points of the SMTP transaction by specifying an ACL to use and defining its conditions in exim.conf. You could start with the HELO string.# Specify the ACL to use after HELO
acl_smtp_helo = check_helo# Conditions for the check_helo ACL:
check_helo:deny message = Gave HELO/EHLO as "friend"
log_message = HELO/EHLO friend
condition = ${if eq {$sender_helo_name}{friend} {yes}{no}}deny message = Gave HELO/EHLO as our IP address
log_message = HELO/EHLO our IP address
condition = ${if eq {$sender_helo_name}{$interface_address} {yes}{no}}accept
NOTE: Pursue HELO checking at your own peril. The HELO is fairly unimportant in the grand scheme of SMTP these days, so don't put too much faith in whatever it contains. Some spam might seem to use a telltale HELO string, but you might be surprised at how many legitimate messages start off with a questionable HELO as well. Anyway, it's just as easy for a spammer to send a proper HELO than it is to send HELO im.a.spammer, so consider yourself lucky if you're able to stop much spam this way.Next, you can perform a check on the sender address or remote host. This shows how to do that after the RCPT TO command; if you reject here, as opposed to rejecting after the MAIL FROM, you'll have better data to log, such as who the message was intended for.
# Specify the ACL to use after RCPT TO
acl_smtp_rcpt = check_recipient# Conditions for the check_recipient ACL
check_recipient:# [...]
drop hosts = /etc/exim_reject_hosts
drop senders = /etc/exim_reject_senders# [ Probably a whole lot more... ]
This example uses two plain text files as blacklists. Add appropriate entries to these files - hostnames/IP addresses to /etc/exim_reject_hosts, addresses to /etc/exim_reject_senders, one entry per line.It is also possible to perform content scanning using a regex against the body of a message, though obviously this can cause Exim to use more CPU than it otherwise would need to, especially on large messages.
# Specify the ACL to use after DATA
acl_smtp_data = check_message# Conditions for the check_messages ACL
check_message:deny message = "Sorry, Charlie: $regex_match_string"
regex = ^Subject:: .*Lower your self-esteem by becoming a sysadminaccept
Fix SMTP-Auth for Pine
If pine can't use SMTP authentication on an Exim host and just returns an "unable to authenticate" message without even asking for a password, add the following line to exim.conf:begin authenticators
fixed_plain:
driver = plaintext
public_name = PLAIN
server_condition = "${perl{checkuserpass}{$1}{$2}{$3}}"
server_set_id = $2
> server_prompts = :
This was a problem on CPanel Exim builds awhile ago, but they seem to have added this line to their current stock configuration.Log the subject line
This is one of the most useful configuration tweaks I've ever found for Exim. Add this to exim.conf, and you can log the subject lines of messages that pass through your server. This is great for troubleshooting, and for getting a very rough idea of what messages may be spam.log_selector = +subject
Reducing or increasing what is logged.Disable identd lookups
Frankly, I don't think identd has been useful for a long time, if ever. Identd relies on the connecting host to confirm the identity (system UID) of the remote user who owns the process that is making the network connection. This may be of some use in the world of shell accounts and IRC users, but it really has no place on a high-volume SMTP server, where the UID is often simply "mail" or whatever the remote MTA runs as, which is useless to know. It's overhead, and results in nothing but delays while the identd query is refused or times out. You can stop your Exim server from making these queries by setting the timeout to zero seconds in exim.conf:rfc1413_query_timeout = 0s
Disable Attachment Blocking
To disable the executable-attachment blocking that many Cpanel servers do by default but don't provide any controls for on a per-domain basis, add the following block to the beginning of the /etc/antivirus.exim file:if $header_to: matches "example\.com|example2\.com"
then
finish
endif
It is probably possible to use a separate file to list these domains, but I haven't had to do this enough times to warrant setting such a thing up.Searching the logs with exigrep
The exigrep utility (not to be confused with exiqgrep) is used to search an exim log for a string or pattern. It will print all log entries with the same internal message-id as those that matched the pattern, which is very handy since any message will take up at least three lines in the log. exigrep will search the entire content of a log entry, not just particular fields.One can search for messages sent from a particular IP address:
root@localhost# exigrep '<= .* \[12.34.56.78\] ' /path/to/exim_log
Search for messages sent to a particular IP address:root@localhost# exigrep '=> .* \[12.34.56.78\]' /path/to/exim_log
This example searches for outgoing messages, which have the "=>" symbol, sent to "user@domain.tld". The pipe to grep for the "<=" symbol will match only the lines with information on the sender - the From address, the sender's IP address, the message size, the message ID, and the subject line if you have enabled logging the subject. The purpose of doing such a search is that the desired information is not on the same log line as the string being searched for.root@localhost# exigrep '=> .*user@domain.tld' /path/to/exim_log | fgrep '<='
Generate and display Exim stats from a logfile:root@localhost# eximstats /path/to/exim_mainlog
Same as above, with less verbose output:root@localhost# eximstats -ne -nr -nt /path/to/exim_mainlog
Same as above, for one particular day:root@localhost# fgrep YYYY-MM-DD /path/to/exim_mainlog | eximstats
Bonus!
To delete all queued messages containing a certain string in the body:root@localhost# grep -lr 'a certain string' /var/spool/exim/input/ | \
sed -e 's/^.*\/\([a-zA-Z0-9-]*\)-[DH]$/\1/g' | xargs exim -Mrm
Note that the above only delves into /var/spool/exim in order to grep for queue files with the given string, and that's just because exiqgrep doesn't have a feature to grep the actual bodies of messages. If you are deleting these files directly, YOU ARE DOING IT WRONG! Use the appropriate exim command to properly deal with the queue.If you have to feed many, many message-ids (such as the output of an `exiqgrep -i` command that returns a lot of matches) to an exim command, you may exhaust the limit of your shell's command line arguments. In that case, pipe the listing of message-ids into xargs to run only a limited number of them at once. For example, to remove thousands of messages sent from joe@example.com:
root@localhost# exiqgrep -i -f '<joe@example.com>' | xargs exim -Mrm
Speaking of "DOING IT WRONG" -- Attention, CPanel forum readers
I get a number of hits to this page from a link in this post at the CPanel forums. The question is:Due to spamming, spoofing from fields, etc., etc., etc., I am finding it necessary to spend more time to clear the exim queue from time to time. [...] what command would I use to delete the queue
The answer is: Just turn exim off, because your customers are better off knowing that email simply isn't running on your server, than having their queued messages deleted without notice.Or, figure out what is happening. The examples given in that post pay no regard to the legitimacy of any message, they simply delete everything, making the presumption that if a message is in the queue, it's junk. That is total fallacy. There are a number of reasons legitimate mail can end up in the queue. Maybe your backups or CPanel's "upcp" process are running, and your load average is high -- exim goes into a queue-only mode at a certain threshold, where it stops trying to deliver messages as they come in and just queues them until the load goes back down. Or, maybe it's an outgoing message, and the DNS lookup failed, or the connection to the domain's MX failed, or maybe the remote MX is busy or greylisting you with a 4xx deferral. These are all temporary failures, not permanent ones, and the whole point of having temporary failures in SMTP and a mail queue in your MTA is to be able to try again after awhile.
Exim already purges messages from the queue after the period of time specified in exim.conf. If you have this value set appropriately, there is absolutely no point in removing everything from your queue every day with a cron job. You will lose legitimate mail, and the sender and recipient will never know if or why it happened. Do not do this!
If you regularly have a large number of messages in your queue, find out why they are there. If they are outbound messages, see who is sending them, where they're addressed to, and why they aren't getting there. If they are inbound messages, find out why they aren't getting delivered to your user's account. If you need to delete some, use exiqgrep to pick out just the ones that should be deleted.
Reload the configuration
After making changes to exim.conf, you need to give the main exim pid a SIGHUP to re-exec it and have the configuration re-read. Sure, you could stop and start the service, but that's overkill and causes a few seconds of unnecessary downtime. Just do this:root@localhost# kill -HUP `cat /var/spool/exim/exim-daemon.pid`
You should then see something resembling the following in exim_mainlog:pid 1079: SIGHUP received: re-exec daemon
exim 4.52 daemon started: pid=1079, -q1h, listening for SMTP on port 25 (IPv4)
Read The Fucking Manual
The Exim Home PageDocumentation For Exim
The Exim Specification - Version 4.5x
Exim command line arguments
Any questions?
Well, don't ask me! I'm one guy, with just enough time and Exim skills to keep my own stuff running okay. There are several (perhaps even dozens) of people on the Internet who know way more than me, and who are willing to help out random strangers. Check into the Exim users mailing list, or one of the many web-based gateways to that list. And good luck. -
xargs is a command on Unix and most Unix-like operating systems used to build and execute commands from standard input. It converts input from standard input into arguments to a command.
Some commands such as
grepandawkcan take input either as command-line arguments or from the standard input. However, others such ascpandechocan only take input as arguments, which is why xargs is necessary.Contents
Examples[edit]
One use case of the xargs command is to remove a list of files using the rm command. Under the Linux kernel before version 2.6.23, and under many other Unix-like systems, arbitrarily long lists of parameters cannot be passed to a command,[1] so the command may fail with an error message of "Argument list too long" (meaning that the exec system call's limit on the length of a command line was exceeded):
rm /path/*
or
rm $(find /path -type f)
This can be rewritten using the
xargscommand to break the list of arguments into sublists small enough to be acceptable:find /path -type f -print | xargs rmIn the above example, the
findutility feeds the input ofxargswith a long list of file names.xargsthen splits this list into sublists and callsrmonce for every sublist.xargs can also be used to parallelize operations with the
-P maxprocsargument to specify how many parallel processes should be used to execute the commands over the input argument lists. However, the output streams may not be synchronized. This can be overcome by using an--output fileargument where possible, and then combining the results after processing. The following example queues 24 processes and waits on each to finish before launching another.find /path -name '*.foo' | xargs -P 24 -I '{}' /cpu/bound/process '{}' -o '{}'.out
xargs often covers the same functionality as the backquote (`) feature of many shells, but is more flexible and often also safer, especially if there are blanks or special characters in the input. It is a good companion for commands that output long lists of files such as
find,locateandgrep, but only if you use-0, sincexargswithout-0deals badly with file names containing ', " and space. GNU Parallel is a similar tool that offers better compatibility with find, locate and grep when file names may contain ', ", and space (newline still requires-0).Placement of arguments[edit]
-I option[edit]
The xargs command offers options to insert the listed arguments at some position other than the end of the command line. The -I option to xargs takes a string that will be replaced with the supplied input before the command is executed. A common choice is %.
$ mkdir ~/backups $ find /path -type f -name '*~' -print0 | xargs -0 -I % cp -a % ~/backups
Shell trick[edit]
Another way to achieve a similar effect is to use a shell as the launched command, and deal with the complexity in that shell, for example:
$ mkdir ~/backups $ find /path -type f -name '*~' -print0 | xargs -0 bash -c 'for filename; do cp -a "$filename" ~/backups; done' bash
The word
bashat the end of the line is interpreted bybash -cas special parameter $0. If the wordbashweren't present, the name of the first matched file would be assigned to$0and the file wouldn't be copied to~/backups. Any word can be used instead ofbash, but since$0usually expands to the name of the shell or shell script being executed,bashis a good choice.Separator problem[edit]
Many Unix utilities are line-oriented. These may work with
xargsas long as the lines do not contain',", or a space. Some of the Unix utilities can use NUL as record separator (e.g. Perl (requires-0and\0instead of\n),locate(requires using-0),find(requires using-print0),grep(requires-zor-Z),sort(requires using-z)). Using-0forxargsdeals with the problem, but many Unix utilities cannot use NUL as separator (e.g.head,tail,ls,echo,sed,tar -v,wc,which).But often people forget this and assume
xargsis also line-oriented, which is not the case (per defaultxargsseparates on newlines and blanks within lines, substrings with blanks must be single- or double-quoted).The separator problem is illustrated here:
touch important_file touch 'not important_file' find . -name not\* | tail -1 | xargs rm mkdir -p '12" records' find \! -name . -type d | tail -1 | xargs rmdir
Running the above will cause
important_fileto be removed but will remove neither the directory called12" records, nor the file callednot important_file.The proper fix is to use the
-print0option, buttail(and other tools) do not support NUL-terminated strings:touch important_file touch 'not important_file' find . -name not\* -print0 | xargs -0 rm mkdir -p '12" records' find \! -name . -type d -print0 | xargs -0 rmdir
When using the
-print0option, entries are separated by a null character instead of an end-of-line. This is equivalent to the more verbose command:find . -name not\* | tr \\n \\0 | xargs -0 rm
or shorter, by switching
xargsto line-oriented mode with the-d(delimiter) option:find . -name not\* | xargs -d '\n' rm
but in general using the
-0option should be preferred, since newlines in filenames are still a problem.GNU
parallelis an alternative toxargsthat is designed to have the same options, but be line-oriented. Thus, using GNU Parallel instead, the above would work as expected.[2]For Unix environments where
xargsdoes not support the-0option (e.g. Solaris, AIX), the following can not be used as it does not deal with ' and " (GNUparallelwould work on Solaris, though):find . -name not\* | sed 's/ /\\ /g' | xargs rm
For Solaris, do not use these examples to fix file perms as they do not deal correctly with names such as 12" records (GNU
parallelinstead ofxargswould work, though):find . -type d -print | sed -e 's/^/"/' -e 's/$/"/' | xargs chmod 755 find . -type f -print | sed -e 's/^/"/' -e 's/$/"/' | xargs chmod 644
Operating on a subset of arguments at a time[edit]
One might be dealing with commands that can only accept one or maybe two arguments at a time. For example, the
diffcommand operates on two files at a time. The-noption toxargsspecifies how many arguments at a time to supply to the given command. The command will be invoked repeatedly until all input is exhausted. Note that on the last invocation one might get fewer than the desired number of arguments if there is insufficient input. Usexargsto break up the input into two arguments per line:$ echo {0..9} | xargs -n 2 0 1 2 3 4 5 6 7 8 9
In addition to running based on a specified number of arguments at a time, one can also invoke a command for each line of input with the
-L 1option. One can use an arbitrary number of lines at a time, but one is most common. Here is how one mightdiffevery git commit against its parent.[3]$ git log --format="%H %P" | xargs -L 1 git diff
Encoding problem[edit]
The argument separator processing of
xargsis not the only problem with using thexargsprogram in its default mode. Most Unix tools which are often used to manipulate filenames (for examplesed,basename,sort, etc.) are text processing tools. However, Unix path names are not really text. Consider a path name /aaa/bbb/ccc. The /aaa directory and its bbb subdirectory can in general be created by different users with different environments. That means these users could have a different locale setup, and that means that aaa and bbb do not even necessarily have to have the same character encoding. For example, aaa could be in UTF-8 and bbb in Shift JIS. As a result, an absolute path name in a Unix system may not be correctly processable as text under a single character encoding. Tools which rely on their input being text may fail on such strings.One workaround for this problem is to run such tools in the C locale, which essentially processes the bytes of the input as-is. However, this will change the behavior of the tools in ways the user may not expect (for example, some of the user's expectations about case-folding behavior may not be met).
https://en.wikipedia.org/wiki/Xargs
-
Pipes: A Brief Introduction
A pipe is a form of redirection that is used in Linux and other Unix-like operating systems to send the output of one program to another program for further processing.
Redirection is the transferring of standard output to some other destination, such as another program, a file or a printer, instead of the display monitor (which is its default destination). Standard output, sometimes abbreviated stdout, is the destination of the output from command line (i.e., all-text mode) programs in Unix-like operating systems.
Pipes are used to create what can be visualized as a pipeline of commands, which is a temporary direct connection between two or more simple programs. This connection makes possible the performance of some highly specialized task that none of the constituent programs could perform by themselves. A command is merely an instruction provided by a user telling a computer to do something, such as launch a program. The command line programs that do the further processing are referred to as filters.
This direct connection between programs allows them to operate simultaneously and permits data to be transferred between them continuously rather than having to pass it through temporary text files or through the display screen and having to wait for one program to be completed before the next program begins.
HistoryPipes rank alongside the hierarchical file system and regular expressions as one of the most powerful yet elegant features of Unix-like operating systems. The hierarchical file system is the organization of directories in a tree-like structure which has a single root directory (i.e., a directory that contains all other directories). Regular expressions are a pattern matching system that uses strings (i.e., sequences of characters) constructed according to pre-defined syntax rules to find desired patterns in text.
Pipes were first suggested by M. Doug McIlroy, when he was a department head in the Computing Science Research Center at Bell Labs, the research arm of AT&T (American Telephone and Telegraph Company), the former U.S. telecommunications monopoly. McIlroy had been working on macros since the latter part of the 1950s, and he was a ceaseless advocate of linking macros together as a more efficient alternative to series of discrete commands. A macro is a series of commands (or keyboard and mouse actions) that is performed automatically when a certain command is entered or key(s) pressed.
McIlroy's persistence led Ken Thompson, who developed the original UNIX at Bell Labs in 1969, to rewrite portions of his operating system in 1973 to include pipes. This implementation of pipes was not only extremely useful in itself, but it also made possible a central part of the Unix philosophy, the most basic concept of which is modularity (i.e., a whole that is created from independent, replaceable parts that work together efficiently).
ExamplesA pipe is designated in commands by the vertical bar character, which is located on the same key as the backslash on U.S. keyboards. The general syntax for pipes is:
command_1 | command_2 [| command_3 . . . ]This chain can continue for any number of commands or programs.A very simple example of the benefits of piping is provided by the dmesg command, which repeats the startup messages that scroll through the console (i.e., the all-text, full-screen display) while Linux is booting (i.e., starting up). dmesg by itself produces far too many lines of output to fit into a single screen; thus, its output scrolls down the screen at high speed and only the final screenful of messages is easily readable. However, by piping the output of dmesg to the filter less, the startup messages can conveniently be viewed one screenful at a time, i.e.,dmesg | lessless allows the output of dmesg to be moved forward one screenful at a time by pressing the SPACE bar and back one screenful at a time by pressing the b key. The command can be terminated by pressing the q key. (The more command could have been used here instead of less; however, less is newer than more and has additional functions, including the ability to return to previous pages of the output.)The same result could be achieved by first redirecting the output of dmesg to a temporary file and then displaying the contents of that file on the monitor. For example, the following set of two commands uses the output redirection operator (designated by a rightward facing angle bracket) to first send the output of dmesg to a text file called tempfile1 (which will be created by the output redirection operator if it does not already exist), and then it uses another output redirection operator to transfer the output of tempfile1 to the display screen:dmesg > tempfile1
tempfile1 > lessHowever, redirection to a file as an intermediate step is clearly less efficient, both because two separate commands are required and because the second command must await the completion of the first command before it can begin.The use of two pipes to chain three commands together could make the above example even more convenient for some situations. For example, the output of dmesg could first be piped to the sort filter to arrange it into alphabetic order before piping it to less:dmesg | sort -f | lessThe -f option tells sort to disregard case (i.e., whether letters are lower case or upper case) while sorting.Likewise, the output of the ls command (which is used to list the contents of a directory) is commonly piped to the the less (or more) command to make the output easier to read, i.e.,ls -al | lessorls -al | morels reports the contents of the current directory (i.e., the directory in which the user is currently working) in the absence of any arguments(i.e., input data in the form of the names of files or directories). The -l option tells ls to provide detailed information about each item, and the -a option tells ls to include all files, including hidden files (i.e., files that are normally not visible to users). Because ls returns its output in alphabetic order by default, it is not necessary to pipe its output to the sort command (unless it is desired to perform a different type of sorting, such as reverse sorting, in which case sort's -r option would be used).This could just as easily be done for any other directory. For example, the following would list the contents of the /bin directory (which contains user commands) in a convenient paged format:ls -al /bin | lessThe following example employs a pipe to combine the ls and the wc (i.e., word count) commands in order to show how many filesystem objects(i.e., files, directories and links) are in the current directory:ls | wc -lls lists each object, one per line, and this list is then piped to wc, which, when used with its -l option, counts the number of lines and writes the result to standard output (which, as usual, is by default the display screen).The output from a pipeline of commands can be just as easily redirected to a file (where it is written to that file) or a printer (where it is printed on paper). In the case of the above example, the output could be redirected to a file named, for instance, count.txt:ls | wc -l > count.txtThe output redirection operator will create count.txt if it does not exist or overwrite it if it already exists. (The file does not, of course, require the .txt extension, and it could have just as easily been named count, lines or anything else.)The following is a slightly more complex example of combining a pipe with redirection to a file:echo -e "orange \npeach \ncherry" | sort > fruitThe echo command tells the computer to send the text that follows it to standard output, and its -e option tells the computer to interpret each \n as the newline symbol (which is used to start a new line in the output). The pipe redirects the output from echo -e to the sort command, which arranges it alphabetically, after which it is redirected by the output redirection operator to the file fruit.As a final example, and to further illustrate the great power and flexibility that pipes can provide, the following uses three pipes to search the contents of all of the files in current directory and display the total number of lines in them that contain the string Linux but not the string UNIX:cat * | grep "Linux" | grep -v "UNIX" | wc -lIn the first of the four segments of this pipeline, the cat command, which is used to read and concatenate (i.e., string together) the contents of files, concatenates the contents of all of the files in the current directory. The asterisk is a wildcard that represents all items in a specified directory, and in this case it serves as an argument to cat to represent all objects in the current directory.The first pipe sends the output of cat to the grep command, which is used to search text. The Linux argument tells grep to return only those lines that contain the string Linux. The second pipe sends these lines to another instance of grep, which, in turn, with its -v option, eliminates those lines that contain the string UNIX. Finally, the third pipe sends this output to wc -l, which counts the number of lines and writes the result to the display screen.
"Fake Pipes"A notation similar to the pipes of Unix-like operating systems is used in Microsoft's MS-DOS operating system. However, the method of implementation is completely different. Sometimes the pipe-like mechanism used in MS-DOS is referred to as fake pipes because, instead of running two or more programs simultaneously and channeling the output data from one continuously to the next, MS-DOS uses a temporary buffer file (i.e., section of memory) that first accumulates the entire output from the first program and only then feeds its contents to the next program.This more closely resembles redirection through a file than it does the Unix concept of pipes. It takes more time because the second program cannot begin until the first has been completed, and it also consumes more system resources (i.e., memory and processor time). This approach could be particularly disadvantageous if the first command produces a very large amount of output and/or does not terminate.Created April 29, 2004. Last updated August 23, 2006.
Copyright © 2004 - 2006 The Linux Information Project. All Rights Reserved.http://www.linfo.org/pipes.html
-
Just as when you report spam manually, SpamCop requires the full header information from your email software. It also requires the unmodified body including HTML codes if any and/or MIME information. It depends on your email software. Here are instructions for some of the more popular programs:
Normal email software:
 Microsoft products
Microsoft products
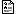 Mac OS X
Mac OS X
Netscape, Mozilla and Thunderbird
Eudora
AOL
Pine
Lotus Notes (v.4.x and v.5.x)
Lotus Notes (v.6.x)
Pegasus Mail
WebTV
Claris Emailer
kmail (KDE Desktop)
GNU/Emacs integrated email
Mail Warrior
Juno Version 4+
Mutt
The Bat!
Pronto mail (GTK/unix)
StarOffice
Novell Groupwise
Blitzmail
Fort� Agent
Ximian Evolution
Sylpheed
Web-based email software:
Hotmail and Windows Live Hotmail
Yahoo Mail
Excite web-mail
Netscape Webmail
Blitzmail
Operamail
Lycos Mail (mailcity.com)
Onebox.com
Outlook Web Access
Shawcable Webmail
MSN Premium
GMail
https://www.spamcop.net/fom-serve/cache/19.html -
-
PowerShell Scripts for day to day tasks!
Monday, January 16, 2012
Outlook 2010 forward emails after specific time.
http://danfolkes.com/2011/02/18/outlook-rule-only-at-specific-times/
I wanted to create a forward so that helpdesk email gets forwarded to my phone on my personal email. Setting up helpdesk email was the easy way but it gets 20+ emails every hour during work time. After work hours its pretty much quite. So for those times I wanted the rule.
Rules which needs to be created :-
Quoted from the post below :-
"
The Rule that will check email header* for UTC times. Make sure it’s assigned to the FWD category. And then FWD it:
Apply this rule after the message arrives with '2011 23:' or '2012 18:,2012 19:.....2012 11:' in the message header and assigned to 'FWD' category forward it to 'email@example.com'"
Seach for this string in header.
2012 18:,2012 19:,2012 20:,2012 21:,2012 22:,2012 23:,2012 24:,2012 01:,2012 02:,2012 03:,2012 04:,2012 05:,2012 06:,2012 07:,2012 08:,2012 09:,2012 10:,2012 11:https://usyse.blogspot.com/2012/01/outlook-2010-forward-emails-after.html
-
Outlook Rule : Only at Specific Times
Times

Lets say you want to have a rule in outlook send to you only between specific times in the day.
- Only after 6pm and before 8am
- Only on your lunch hour
- When you are not at work
I will explain this by having emails forward to my cell phone, only when I am normally not at the office. (From 6pm-8am) This way, I will be able to receive important emails that may require special outside assistance.
What I do is:
- Create a special category called FWD
- Use other rules to set messages into the FWD category if I want them forwarded. (Explained Below)
- Then, create a rule to run last in the rules list called FWD Rule
- *Important Part* This will check the time on the messages, if it’s within the specified hours, it will forward the email (Explained Below)
Creating a Rule to set the FWD Category:
Your Rule Description should look something like this. The important part is that it is assigning it to the FWD Category:Apply this rule after the message arrives with 'Emergency from client' in the subject and marked as 'high importance' and assigned to 'FWD' CategoryThe Rule that will email header* for UTC times. Make sure it’s assigned to the FWD category. And then FWD it:
Apply this rule after the message arrives with '2011 23:' or '2011 02:' or ... '2011 10:' in the message header and assigned to 'FWD' category forward it to 'email@example.com'* This should work on most emails, but if you want to look at the email header Right-click on the message in the Inbox and select Message Options.
* I included the 2011 and the colon to make it more specific.UTC Time for 6pm – 8am:
Email Header contained:
X-OriginalArrivalTime: 18 Feb 2011 03:23:52.0368 (UTC)
So I searched for:http://dan.folkes.me/2011/02/18/outlook-rule-only-at-specific-times/2011 23:,2011 01:,2011 02:,2011 03:,2011 04:,2011 05:,2011 06:,2011 07:,2011 08:,2011 09:,2011 10:,2011 11:
-
-
-
This post is reposted from the Microsoft Azure Blog : What is Artificial Intelligence? <azure.microsoft.com/blog/what-is-artificial-intelligence/>
Aug 9th 2018, 12:00, by Theo van Kraay
It has been said that Artificial Intelligence will define the next generation of software solutions. If you are even remotely involved with technology, you will almost certainly have heard the term with increasing regularity over the last few years. It is likely that you will also have heard different definitions for Artificial Intelligence offered, such as:
*“The ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings.”* – Encyclopedia Britannica
*“Intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans.”* – Wikipedia
How useful are these definitions? What exactly are “tasks commonly associated with intelligent beings”? For many people, such definitions can seem too broad or nebulous. After all, there are many tasks that we can associate with human beings! What exactly do we mean by “intelligence” in the context of machines, and how is this different from the tasks that many traditional computer systems are able to perform, some of which may already seem to have some level of *intelligence* in their sophistication? What exactly makes the *Artificial Intelligence* systems of today different from sophisticated software systems of the past?
It could be argued that any attempt to try to define “Artificial Intelligence” is somewhat futile, since we would first have to properly define “intelligence”, a word which conjures a wide variety of connotations. Nonetheless, this article attempts to offer a more accessible definition for what passes as Artificial Intelligence in the current vernacular, as well as some commentary on the nature of today’s AI systems, and why they might be more aptly referred to as “intelligent” than previous incarnations.
Firstly, it is interesting and important to note that the technical difference between what used to be referred to as Artificial Intelligence over 20 years ago and traditional computer systems, is close to zero. Prior attempts to create intelligent systems known as *expert systems* at the time, involved the complex implementation of exhaustive rules that were intended to approximate* intelligent behavior*. For all intents and purposes, these systems did not differ from traditional computers in any drastic way other than having many thousands more lines of code. The problem with trying to replicate human intelligence in this way was that it requires far too many rules and ignores something very fundamental to the way *intelligent beings* make *decisions*, which is very different from the way traditional computers process information.
Let me illustrate with a simple example. Suppose I walk into your office and I say the words “Good Weekend?” Your immediate response is likely to be something like “yes” or “fine thanks”. This may seem like very trivial behavior, but in this simple action you will have immediately demonstrated a behavior that a traditional computer system is completely incapable of. In responding to my question, you have effectively dealt with ambiguity by making a prediction about the correct way to respond. It is not certain that by saying “Good Weekend” I actually intended to ask you whether you had a good weekend. Here are just a few possible* intents* behind that utterance:
– Did you have a good weekend? – Weekends are good (generally). – I had a good weekend. – It was a good football game at the weekend, wasn’t it? – Will the coming weekend be a good weekend for you?
And more.
The most likely intended meaning may seem obvious, but suppose that when you respond with “yes”, I had responded with “No, I mean it was a good football game at the weekend, wasn’t it?”. It would have been a surprise, but without even thinking, you will absorb that information into a mental model, correlate the fact that there was an important game last weekend with the fact that I said “Good Weekend?” and adjust the probability of the expected response for next time accordingly so that you can respond correctly next time you are asked the same question. Granted, those aren’t the thoughts that will pass through your head! You happen to have a neural network (aka “your brain”) that will absorb this information automatically and *learn* to respond differently next time.
The key point is that even when you do respond next time, you will still be making a prediction about the correct way in which to respond. As before, you won’t be certain, but if your prediction *fails* again, you will gather new data which leads to my definition of Artificial Intelligence:
“Artificial Intelligence is the ability of a computer system to deal with ambiguity, by making predictions using previously gathered *data*, and learning from errors in those predictions in order to generate newer, more accurate predictions about how to behave in the future”.
This is a somewhat appropriate definition of Artificial Intelligence because it is exactly what AI systems today are doing, and more importantly, it reflects an important characteristic of human beings which separates us from traditional computer systems: human beings are prediction machines. We deal with ambiguity all day long, from very trivial scenarios such as the above, to more convoluted scenarios that involve *playing the odds* on a larger scale. This is in one sense the essence of *reasoning*. We very rarely know whether the way we respond to different scenarios is absolutely correct, but we make reasonable predictions based on past experience.
Just for fun, let’s illustrate the earlier example with some code in R! First, lets start with some data that represents information in your mind about when a particular person has said “good weekend?” to you.
In this example, we are saying that *GoodWeekendResponse* is our *score label* (i.e. it denotes the appropriate response that we want to predict). For modelling purposes, there have to be at least two possible values in this case “yes” and “no”. For brevity, the response in most cases is “yes”.
We can fit the data to a logistic regression model:
library(VGAM) greetings=read.csv(‘c:/AI/greetings.csv’,header=TRUE) fit <- vglm(GoodWeekendResponse~., family=multinomial, data=greetings)
Now what happens if we try to make a prediction on that model, where the expected response is different than we have previously recorded? In this case, I am expecting the response to be “Go England!”. Below, some more code to add the prediction. For illustration we just hardcode the new input data, output is shown in bold:
response <- data.frame(FootballGamePlayed=”Yes”, WorldCup=”Yes”, EnglandPlaying=”Yes”, GoodWeekendResponse=”Go England!!”) greetings <- rbind(greetings, response) fit <- vglm(GoodWeekendResponse~., family=multinomial, data=greetings) prediction <- predict(fit, response, type=”response”) prediction index <- which.max(prediction) df <- colnames(prediction) df[index] * No Yes Go England!! 1 3.901506e-09 0.5 0.5 > index <- which.max(prediction) > df <- colnames(prediction) > df[index] [1] “Yes”*
The initial prediction “yes” was wrong, but note that in addition to predicting against the new data, we also incorporated the actual response back into our existing model. Also note, that the new response value “Go England!” has been *learnt*, with a probability of 50 percent based on current data. If we run the same piece of code again, the probability that “Go England!” is the right response based on prior data increases, so this time our model *chooses* to respond with “Go England!”, because it has finally learnt that this is most likely the correct response!
* No Yes Go England!! 1 3.478377e-09 0.3333333 0.6666667 > index <- which.max(prediction) > df <- colnames(prediction) > df[index] [1] “Go England!!”*
Do we have Artificial Intelligence here? Well, clearly there are different *levels* of intelligence, just as there are with human beings. There is, of course, a good deal of nuance that may be missing here, but nonetheless this very simple program will be able to react, with limited accuracy, to data coming in related to one very specific topic, as well as learn from its mistakes and make adjustments based on predictions, without the need to develop exhaustive rules to account for different responses that are expected for different combinations of data. This is this same principle that underpins many AI systems today, which, like human beings, are mostly sophisticated prediction machines. The more sophisticated the machine, the more it is able to make accurate predictions based on a complex array of data used to *train* various models, and the most sophisticated AI systems of all are able to continually learn from faulty assertions in order to improve the accuracy of their predictions, thus exhibiting something approximating human *intelligence*. Machine learning
You may be wondering, based on this definition, what the difference is between *machine learning* and *Artificial intelligence*? After all, isn’t this exactly what machine learning algorithms do, make predictions based on data using statistical models? This very much depends on the definition of *machine learning*, but ultimately most machine learning algorithms are* trained* on static data sets to produce predictive models, so machine learning algorithms only facilitate part of the dynamic in the definition of AI offered above. Additionally, machine learning algorithms, much like the contrived example above typically focus on specific scenarios, rather than working together to create the ability to deal with *ambiguity* as part of an *intelligent system*. In many ways, machine learning is to AI what neurons are to the brain. A building block of intelligence that can perform a discreet task, but that may need to be part of a composite *system* of predictive models in order to really exhibit the ability to deal with ambiguity across an array of behaviors that might approximate to *intelligent behavior*. Practical applications
There are number of practical advantages in building AI systems, but as discussed and illustrated above, many of these advantages are pivoted around “time to market”. AI systems enable the embedding of complex decision making without the need to build exhaustive rules, which traditionally can be very time consuming to procure, engineer and maintain. Developing systems that can “learn” and “build their own rules” can significantly accelerate organizational growth.
Microsoft’s Azure cloud platform offers an array of discreet and granular services in the AI and Machine Learning domain <docs.microsoft.com/en-us/azure/#pivot=products&panel=ai>, that allow AI developers and Data Engineers to avoid re-inventing wheels, and consume re-usable APIs. These APIs allow AI developers to build systems which display the type of *intelligent behavior* discussed above.
If you want to dive in and learn how to start building intelligence into your solutions with the Microsoft AI platform, including pre-trained AI services like Cognitive Services and the Bot Framework, as well as deep learning tools like Azure Machine Learning, Visual Studio Code Tools for AI, and Cognitive Toolkit, visit AI School <aischool.microsoft.com/learning-paths>. -

despite proper DKIM/SPF setup and appropriate Spam Assassin configuration as well as
cPanel > Mail section > Default Address
set to
Current Setting: :fail: No Such User Here
I have a friend receiving self sent emails that are obviously spam
You would think this is common and easy to tackle but ... your could not be more wrong than that !
https://forums.cpanel.net/threads/self-sent-spam.334831/
https://forums.cpanel.net/threads/spam-sent-to-self.608551/
https://luxsci.com/blog/save-yourself-from-yourself-stop-spam-from-your-own-address.html
So, what do we recommend?
The simplest way to take care of this situation is to:
- Use Email Filtering systems that treat SPF and DKIM properly, to stop this kind of spam.
- Make sure that any catch-all email aliases are turned off (the ones that accept all email to unknown/undefined addresses in your domain and deliver them to you anyway — these are giant spam traps).
- Make sure that your email address and your domain name are NOT on your own Spam Filter allow or white list(s).
- Make sure that, if you are using your address book as a source of addresses to allow, that your own address is NOT in there (or else don’t white list your address book).
- Add the Internet IP address(es) of the servers from which you do send email to your allow list, if possible. Contact your email provider for assistance in obtaining this list and updating your filters with it.
- Add SPF to your domain’s DNS. Make it strict (i.e. “-all”)
- Use DKIM. Make it strict (i.e. “dkim=discardable”). See our DKIM Generator.
- Setup DMARC to enable servers to properly handle SPF and DKIM failures.
- Consider using Authenticated Received Chain (ARC) once it is available to you. It will provide further levels of validation to handle problems with SPF and DKIM.
If you want to go further, consider use of technologies such as PGP or S/MIME for cryptographic signing of individual messages and consider “closed” email systems … where only the participants can send messages to each other.
-
What's new in version 4.3.5
Version 4.3.5 is a small maintenance update to fix issues reported since 4.3.4.
Also included: 4.3.4- Added a filter to view members that have opt-in for bulk mail in the ACP, and an option to opt-out those members
- Bug fixes
-
http://www.youronlinechoices.com/gr/your-choices
Διαχείριση Επιλογών
Παρακάτω θα βρείτε μερικές από τις εταιρείες που συνεργάζονται με ιστοσελίδες για να συλλέξουν και να χρησιμοποιήσουν πληροφορίες για να παρέχουν συμπεριφορική διαφήμιση.
Παρακαλούμε χρησιμοποιήστε τα κουμπιά για να ρυθμίσετε τις προτιμήσεις σας. Μπορείτε να ενεργοποιήσετε ή να απενεργοποιήσετε όλες τις εταιρείες, ή να ρυθμίσετε τις προτιμήσεις σας για συγκεκριμένες εταιρείες. Κάνοντας κλικ στο μπορείτε να μάθετε περισσότερα για τη συγκεκριμένη εταιρεία καθώς και αν είναι ενεργοποιημένη ή όχι στον browser που χρησιμοποιείτε. Αν αντιμετωπίζετε προβλήματα, παρακαλούμε συμβουλευθείτε τη Βοήθεια.
μπορείτε να μάθετε περισσότερα για τη συγκεκριμένη εταιρεία καθώς και αν είναι ενεργοποιημένη ή όχι στον browser που χρησιμοποιείτε. Αν αντιμετωπίζετε προβλήματα, παρακαλούμε συμβουλευθείτε τη Βοήθεια.
-
 These settings apply when you're using this browser and deviceSIGN IN to control settings for personalized ads across all of your browsers and devices
These settings apply when you're using this browser and deviceSIGN IN to control settings for personalized ads across all of your browsers and devices Ads Personalization on Google SearchSee more useful ads when you're using Google SearchThe way Google saves your ad settings has changed. Learn more about how Google uses cookies for ad personalizationAds Personalization Across the WebSee more useful ads on YouTube and the 2+ million websites that partner with Google to show ads
Ads Personalization on Google SearchSee more useful ads when you're using Google SearchThe way Google saves your ad settings has changed. Learn more about how Google uses cookies for ad personalizationAds Personalization Across the WebSee more useful ads on YouTube and the 2+ million websites that partner with Google to show adshttps://adssettings.google.com/anonymous
-
We ran into an interesting MySQL character encoding issue at Crowd Favorite today while working to upgrade and launch a new client site.
Here is what we were trying to do: copy the production database to the staging database so we could properly configure and test everything before pushing the new site live. Pretty simple right? It was, until we noticed a bunch of weird character encoding issues on the staging site.

It turned out that while the database tables were set to a Latin-1 (latin1), the content that populated those tables was encoded as UTF-8 (utf8). A variety of attempts to fix this failed, but what succeeded was as follows:
- Export the data as Latin-1. Because MySQL knows that the table is already using a Latin-1 encoding, it will do a straight export of the data without trying to convert the data to another character set. If you try to export as UTF-8, MySQL appears to attempt to convert the (supposedly) Latin-1 data to UTF-8 – resulting in double encoded characters (since the data was actually already UTF-8).
- Change the character set in the exported data file from ‘latin1’ to ‘utf8’. Since the dumped data was not converted during the export process, it’s actually UTF-8 encoded data.
-
Create your new table as UTF-8 If your
CREATE TABLEcommand is in your SQL dump file, change the character set from ‘latin1’ to ‘utf8’. - Import your data normally. Since you’ve got UTF-8 encoded data in your dump file, the declared character set in the dump file is now UTF-8, and the table you’re importing into is UTF-8, everything will go smoothly.
I can confirm that a half-dozen or so variations on the above do not work. This includes
INSERT INTO newdb.newtable SELECT * FROM olddb.oldtable;.Also, if you’re doing this for a WordPress1 site (like we were), keep in mind that copying over the production database will generally mean that WP-Cache is enabled. You’ll want to remember to turn that off. Yeah.

- This is a fairly common issue in older WordPress installs because the MySQL database default is commonly Latin-1, and older versions of WordPress did not specify the character set when creating the database tables (so they would default to Latin-1) and the default encoding in the WordPress settings is UTF-8. [back]
http://alexking.org/blog/2008/03/06/mysql-latin1-utf8-conversion
-
Since the Poodle vulnerability (SSLv3) a number of clients disabling SSLv3 on CentOS 5 breaks compatibility with external sites and applications such as WHMCS and PayPal IPN. This is because TLS1.0 will be the only supported method.
In order to support the TLS1.1 and TLS1.2 you can follow the steps below to force the use of the newer version of openssl:
First we need to get the latest openssl version (all links provided in this article are the latest at the time of writing)
wget 'http://www.openssl.org/source/openssl-1.0.1j.tar.gz'
tar -zxf openssl-1.0.1j.tar.gz
cd openssl-1.0.1j
./config shared -fPIC
make
make installInstall latest curl to /usr/local/ssl
rm -rf /opt/curlssl
wget 'http://curl.haxx.se/download/curl-7.38.0.tar.gz'
tar -zxf curl-7.38.0.tar.gz
cd curl-7.38.0
./configure --prefix=/opt/curlssl --with-ssl=/usr/local/ssl --enable-http --enable-ftp LDFLAGS=-L/usr/local/ssl/lib CPPFLAGS=-I/usr/local/ssl/include
make
make installNow we need to configure EasyApache to use what we’ve done, we will do this by creating two files.
cd /var/cpanel/easy/apache/rawopts
touch all_php5
touch Apache2_4Edit all_php5 in your favourite text editor
--enable-ssl
--with-ssl=/usr/local/ssl
--with-curl=/opt/curlssl
LDFLAGS=-L/usr/local/ssl/lib
CPPFLAGS=-I/usr/local/ssl/includeEdit Apache2_4 in your favourite text editor
--with-ssl=/usr/local/ssl
LDFLAGS=-L/usr/local/ssl/lib
CPPFLAGS=-I/usr/local/ssl/includeGo into WHM goto EasyApache, Select build from current profile or customise as you require. Once completed you now have TLS 1.2 that will survive upgrades!
For forwarding secrecy and high encryption ratings add the following from WHM > Apache Configuration > Include Editor > Pre VirtualHost Include, choose either all versions or your current version and paste the below code into the box
SSLProtocol -SSLv2 -SSLv3 +TLSv1.2 +TLSv1.1 +TLSv1
SSLCompression off
SSLHonorCipherOrder on
SSLCipherSuite ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES256-GCM-SHA384:AES256-GCM-SHA384:DHE-RSA-AES256-SHA256:DHE-RSA-CAMELLIA256-SHA:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-SHA256:AES128-GCM-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:!NULL:!eNULL:!aNULL:!DSS:-LOW:RSA+RC4+SHAhttps://www.gbservers.co.uk/2014/10/19/centos-5-tls-1-2-support-cpanelwhm/
-
edit
/etc/yum.repos.d/CentOS-Base.repo
and replace with
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#[base]
name=CentOS-$releasever - Base
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
baseurl=http://vault.centos.org/5.11/os/x86_64/
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5#released updates
[updates]
name=CentOS-$releasever - Updates
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates
baseurl=http://vault.centos.org/5.11/updates/x86_64/
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras
baseurl=http://vault.centos.org/5.11/extras/x86_64/
#baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Cent
https://www.centos.org/forums/viewtopic.php?t=62130 -
-
sed -i 's/utf8mb4_unicode_520_ci/utf8_general_ci/' {SQL FILE}
-
all done


Hi Nick Partsalas,
Good news! Version 4.3.4 of Invision Community is now available.
- Added a filter to view members that have opt-in for bulk mail in the ACP, and an option to opt-out those members
- Bug fixes
-
New features for GDPR compliance:
- New feature for administrators to download an XML file of all personal information held.
- New setting to automatically prune IP address records.
- New option when deleting a member to anonymize content submitted by them.
- New setting to automatically add links to privacy policies of integrated third party services such as Google Analytics or Facebook Pixel to your privacy policy if they are enabled.
- Fixes an issue where Calendar events submitted in different timezones to the user may show at the wrong time.
- Other minor bug fixes and improvements.
-
What's new in version 4.3.4
- Added a filter to view members that have opt-in for bulk mail in the ACP, and an option to opt-out those members
- Bug fixes
-
New features for GDPR compliance:
- New feature for administrators to download an XML file of all personal information held.
- New setting to automatically prune IP address records.
- New option when deleting a member to anonymize content submitted by them.
- New setting to automatically add links to privacy policies of integrated third party services such as Google Analytics or Facebook Pixel to your privacy policy if they are enabled.
- Fixes an issue where Calendar events submitted in different timezones to the user may show at the wrong time.
- Other minor bug fixes and improvements.
-
This is a quick guide on how to install both the Redis PHP extension as well as the daemon via SSH.
Installing the Redis daemon:
for CentOS 6/RHEL 6
rpm -ivh https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm yum -y install redis --enablerepo=remi --disableplugin=priorities chkconfig redis on service redis startfor CentOS 7/RHEL 7
rpm -ivh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm yum -y install redis --enablerepo=remi --disableplugin=priorities systemctl enable redis systemctl start redisInstalling the Redis PHP extension for all available versions of PHP.
Copy and paste the entire block into SSH, don't do line by line.for phpver in $(ls -1 /opt/cpanel/ |grep ea-php | sed 's/ea-php//g') ; do cd ~ wget -O redis.tgz https://pecl.php.net/get/redis tar -xvf redis.tgz cd ~/redis* || exit /opt/cpanel/ea-php"$phpver"/root/usr/bin/phpize ./configure --with-php-config=/opt/cpanel/ea-php"$phpver"/root/usr/bin/php-config make clean && make install echo 'extension=redis.so' > /opt/cpanel/ea-php"$phpver"/root/etc/php.d/redis.ini rm -rf ~/redis* done /scripts/restartsrv_httpd /scripts/restartsrv_apache_php_fpmAll done! Check to make sure the PHP extension is loaded in each version of PHP:
Copy and paste the entire block into SSH, don't do line by line.for phpver in $(ls -1 /opt/cpanel/ |grep php | sed 's/ea-php//g') ; do echo "PHP $phpver" ; /opt/cpanel/ea-php$phpver/root/usr/bin/php -i |grep "Redis Support" doneOutput should be:
PHP 55 Redis Support => enabled PHP 56 Redis Support => enabled PHP 70 Redis Support => enabled PHP 71 Redis Support => enabledEnjoy!
https://help.bigscoots.com/cpanel/cpanel-easyapache-4-installing-redis-and-redis-php-extension

Setting Up Logrotate on RedHat Linux
in Διαχείριση Linux server
Posted · Report reply
Introduction
Logrotate is a utility designed for administrators who manage servers producing a high volume of log files to help them save some disk space as well as to avoid a potential risk making a system unresponsive due to the lack of disk space. Normally, a solution to avoid this kind of problem is to setup a separate partition or logical volume for a /var mount point. However, logrotate may also be a viable solution to this problem especially if it is too late to move all logs under different partition. In this article we will talk about usage and configuration of logrotate on RedHat / CentOS Linux server.
What is Logrotate
Logrotate provides an ability for a system administrator to systematically rotate and archive any log files produced by the system and thus reducing a operating system's disk space requirement. By default logrotate is invoked once a day using a cron scheduler from location /etc/cron.daily/
Configuring Logrotate
Logrotate's configuration is done by editing two separate configuration files:
The main logrotate.conf file contains a generic configuration. Here is a default logrotate configuration file logrotate.conf:
1 weekly 2 rotate 4 3 create 4 dateext 5 include /etc/logrotate.d 6 /var/log/wtmp { 7 monthly 8 create 0664 root utmp 9 minsize 1M 10 rotate 1 11 }As opposed to logrotate.conf a directory /etc/logrotate.d/ contains a specific service configuration files used by logrotate. In the next section we will create a sample skeleton logrotate configuration.
Including new service logs to logrotate
In this section we will add new log file into a logrotate configuration. Let's say that we have a log file called:
/var/log/linuxcareer.log
sitting in our /var/log directory that needs to be rotated on daily basis. First we need to create a new logrotate configuration file to accommodate for our new log file:
Insert a following text into /etc/logrotate.d/linuxcareer:
/var/log/linuxcareer.log { missingok notifempty compress size 20k daily create 0600 root root }Here is a line by line explanation of the above logrotate configuration file:
TIP: If you wish to include multiple log files in a single configuration file use wildcard. For example /var/log/mylogs/*.log will instruct logrotate to rotate all log files located in /var/log/mylogs/ with extension .log.
The logrotate utility as quite versatile as it provides many more configuration options. Below, I will list few other configuration options for log rotate. To get a complete list, consult logrotate's manual page:
Testing a new Logrotate configuration
Once you have created a new logrotate configuration file within /etc/logrotate.d:
# cat /etc/logrotate.d/linuxcareer /var/log/linuxcareer.log { missingok notifempty compress size 20k daily create 0600 root root }create some sample log file ( if not existent ! 😞
Once your log file is in place force logrotate to rotate all logs with -f option.
Warning: The above command will rotate all your logs defined in /etc/logrotate.d directory.
Now visit again your /var/log/directory and confirm that your log file was rotated and new log file was created:
As you can see the new empty log file linuxcareer.log was created and old linuxcareer.log file was compressed with gzip and renamed with date extension.
TIP: In order to see a content of your compressed log file you do not need to decompress it first. Use zcat or zless commands which will decompress your log file on fly.
Conclusion
As it was already mentioned previously, the best way to avoid your system being clogged by log files is to create a separate partition/logical volume for your /var/ or even better /var/log directory. However, even then logrotate can help you to save some disk space by compressing your log files. Logrotate may also help you to archive your log files for a future reference by creating an extra copy or by emailing you any newly rotated log files. For more information see logrotate's manual page:
https://linuxconfig.org/setting-up-logrotate-on-redhat-linux